सोने के बाद चांदी सबसे कीमती धातु मानी जाती है। कई परिवारों में खुशी के मौकों पर सोने-चांदी की चेन-अंगूठियां ली-दी जाती हैं (या पहनी जाती हैं)। बेशक, चांदी सोने से सस्ती है।
लेकिन जब उद्योग (silver in industry) और ऊर्जा उत्पादन (silver in clean energy) में उपयोग की बात आती है तो चांदी सोने को पछाड़ देती है। पूरे भारत में चांदी का इस्तेमाल छतों पर लगे सौर पैनलों (solar panels) के माध्यम से सौर ऊर्जा को कैद करने में किया जाता है। इससे पूरे देश में सालाना लगभग 108 गीगावॉट स्वच्छ एवं हरित बिजली पैदा होती है। यह मात्रा कोयले से पैदा होने वाली बिजली की लगभग 10 प्रतिशत है। इसके अलावा, भारत की लगभग 1.4 अरब आबादी द्वारा इस्तेमाल किए जाने वाले मोबाइल फोन (silver in mobile phones) में विद्युत चालन और भंडारण के लिए चांदी का इस्तेमाल किया जाता है। हर मोबाइल फोन में लगभग 100-200 मिलीग्राम चांदी होती है। इसी तरह, एक सामान्य लैपटॉप में 350 मिलीग्राम चांदी उपयोग होती है, और वर्तमान में भारत में लगभग 5 करोड़ लैपटॉप हैं।
यदि भारत में मोबाइल फोन और लैपटॉप इतनी संख्या में हैं तो आप अंदाज़ा लगा सकते हैं कि पूरी दुनिया में इनकी संख्या कितनी होगी। अनुमान है कि मोबाइल-लैपटॉप या ऐसी ही अन्य चीज़ों में पूरे विश्व में लगभग 7275 मीट्रिक टन चांदी लगती है। लेकिन (इन उपकरणों के खराब होने पर इनसे) बमुश्किल 15 प्रतिशत चांदी ही वापस निकालकर पुनर्चक्रित (silver recycling) की जाती है। जब कोई फोन या कंप्यूटर खराब हो जाता है या फेंक दिया जाता है तो उसमें मौजूद चांदी भी कूड़े में चली जाती है। काश! हम इन बेकार उपकरणों से यह चांदी वापिस निकाल पाते…
यह तो साफ है कि स्वच्छ ऊर्जा उत्पादन में चांदी (silver in renewable energy) एक महत्वपूर्ण भूमिका निभाती है। इस संदर्भ में मारिया स्मिरनोवा एक हालिया रिपोर्ट स्प्रॉट सिल्वर रिपोर्ट (Sprott Silver Report) में लिखती हैं कि जैसे-जैसे अधिकाधिक देश सौर पैनलों का उपयोग करके अक्षय ऊर्जा बनाएंगे, वैसे-वैसे चांदी की मांग (silver demand in solar industry) में लगातार वृद्धि होगी। वे आगे बताती हैं कि भले ही कुछ समूह सौर ऊर्जा के लिए अन्य धातुओं (जैसे लीथियम, कोबाल्ट और निकल) का उपयोग करने पर विचार कर रहे हैं, फिर भी स्वच्छ और हरित ऊर्जा उत्पादन में चांदी एक प्रमुख भूमिका निभाती है। और, इस साल चांदी की मांग में लगभग 170 प्रतिशत वृद्धि होने की उम्मीद है। इसके अलावा, कारों, बसों और ट्रेनों (electric vehicles) में ईंधन के रूप में पेट्रोल की जगह सौर ऊर्जा का उपयोग होना शुरू हुआ है। स्मिरनोवा आगे बताती हैं कि अंतर्राष्ट्रीय ऊर्जा एजेंसी का अनुमान है कि 2035 तक, दुनिया भर में बिकने वाली हर दूसरी कार इलेक्ट्रिक होगी। इसका मतलब होगा कि हमें और चांदी चाहिए होगी।
इसी संदर्भ में, फिनलैंड के प्रोफेसर टिमो रेपो और उनके साथियों ने अपने शोधपत्र में चांदी को पुनःचक्रित करने की एक कुशल रासायनिक विधि (green silver recovery) प्रस्तुत की है। इस विधि में कार्बनिक वसीय अम्लों (जैसे लिनोलेनिक या ओलिक एसिड) (fatty acids for silver extraction) का उपयोग चांदी निकालने में किया गया है। ये कार्बनिक वसीय अम्ल तिलहन, मेवों और वनस्पति तेलों (जैसे जैतून का तेल या मूंगफली का तेल) में पाए जाते हैं, जिनका दैनिक भोजन में उपयोग होता है।
गौरतलब है कि इलेक्ट्रॉनिक कचरे (e-waste silver recovery) से चांदी को पुन: प्राप्त करना आसान नहीं है: प्रबल अम्लों और साइनाइड के उपयोग की वजह से इस प्रक्रिया में विषाक्त पदार्थ पैदा हो सकते हैं। अन्य धातुओं और मिश्र धातुओं से चांदी को अलग करने की पारंपरिक विधियों का उपयोग करने की बजाय उपरोक्त समूह ने सूरजमुखी, मूंगफली और अन्य तेलों में प्रचुर मात्रा में पाए जाने वाले साधारण असंतृप्त वसीय अम्लों के उपयोग से चांदी को अलग करके पुन: हासिल करने की एक विधि विकसित की है। समूह ने पाया कि इनका पुनर्चक्रण किया जा सकता है और इस प्रकार ये कार्बनिक विलायक और जलीय माध्यम से बेहतर हैं।
शोधकर्ताओं ने इस विधि को ‘शहरी खनन’ (urban mining of silver) में भी कारगर पाया है, जहां कबाड़ या कचरे में फेंके गए कंप्यूटर के मदरबोर्ड और अन्य इलेक्ट्रॉनिक पुर्ज़ों के कचरे से चांदी पुन: निकाली जा सकती है। शोध दल का निष्कर्ष है, “वसीय अम्ल बहुमूल्य बहु-धातु अपशिष्ट के निपटान का उन्नत माध्यम बन सकते हैं।” (स्रोतफीचर्स)
नोट: स्रोत में छपे लेखों के विचार लेखकों के हैं। एकलव्य का इनसे सहमत होना आवश्यक नहीं है। Photo Credit : https://assets.technologynetworks.com/production/dynamic/images/content/399617/fatty-acids-extract-silver-from-electronic-waste-399617-960×540.jpg?cb=13342110
पेड़ और जंगल वातावरण से कार्बन डाईऑक्साइड अवशोषित करते हैं (carbon sequestration by forests) और उसे अपने तने, शाखा, पत्तियों वगैरह की सामग्री के रूप में समो लेते हैं। इसलिए यह जानना बहुत ज़रूरी है कि धरती पर कितना जैविक पदार्थ (बायोमास) (forest biomass estimation) मौजूद है और समय के साथ कैसे बदल रहा है। बायोमास का मतलब है पेड़ों के तने, शाखाओं, पत्तियों और जड़ों में सारे ठोस वनस्पति पदार्थ का कुल वज़न। अभी तक बायोमास का अनुमान लगाने के लिए केवल ज़मीनी सर्वेक्षण (ground survey methods) या साधारण उपग्रह तस्वीरों (basic satellite imagery) का सहारा लिया जाता था, जो सटीक नहीं था।
पृथ्वी पर मौजूद पेड़ों और जंगलों के जैविक द्रव्यमान को मापने के लिए युरोपीय अंतरिक्ष एजेंसी ने ‘बायोमास’ नामक एक उपग्रह (ESA Biomass Satellite) लॉन्च किया है। मिशन अवधि लगभग 5 साल (2030 तक) है। यूके, फ्रांस, इटली और जर्मनी जैसे युरोप के कई देश इस मिशन में प्रमुख भागीदार हैं। इसका मुख्य उद्देश्य यह जानना है कि धरती पर कितनी मात्रा में कार्बन पेड़ों में जमा है (carbon stock in trees) और यह जलवायु परिवर्तन को किस तरह प्रभावित (climate change impact) करता है।
इस उपग्रह से 1.5 ट्रिलियन पेड़ों का बायोमास मापना संभव हो सकेगा। इसका डैटा यह समझने में मदद करेगा कि कितनी मात्रा में कार्बन वातावरण से अवशोषित किया गया है, कौन से क्षेत्र कार्बन स्रोत (उत्सर्जक) (carbon source regions) और कौन से कार्बन सिंक (शोषक) (carbon sink regions) हैं। उदाहरण के लिए अगर अमेज़न के जंगल कट रहे हैं, तो वहां का बायोमास कम होगा और वातावरण में कार्बन डाईऑक्साइड बढ़ेगी। इससे हम जलवायु परिवर्तन (global climate change) और ग्लोबल वार्मिंग के प्रभावों को बेहतर समझ पाएंगे। वैश्विक बायोमास डैटा हर 6 महीने में अपडेट (biomass satellite data update) किया जाएगा।
यह डैटा काफी महत्वपूर्ण होगा: इसका उपयोग पेड़ों के कुल वज़न और मात्रा के आकलन, संग्रहित कार्बन भंडार के मूल्यांकन (carbon storage assessment), वनों की कटाई के वास्तविक प्रभाव, जलवायु मॉडलिंग में सुधार (climate modeling improvement), कार्बन सिंक के रूप में चिंहित क्षेत्रों के लिए पर्यावरण संरक्षण नीति बनाने (environmental policy planning), वैश्विक कार्बन चक्र को समझने और ग्लोबल वार्मिंग को नियंत्रित करने की रणनीति बनाने में किया जा सकेगा। इसके साथ ही जलवायु परिवर्तन मॉडल्स को अधिक सटीक बनाने और वनों की कटाई और पुनर्वनीकरण की निगरानी (deforestation and reforestation monitoring) करने में भी यह उपयोगी होगा। इससे पर्यावरण संरक्षण योजनाओं को मज़बूत बनाने, विकासशील देशों को वनों के प्रबंधन में मदद करने और कार्बन ट्रेडिंग (carbon trading) और जलवायु वित्त (climate finance) में सटीक डैटा प्रदान करने में मदद मिलेगी।
उपग्रहकीविशेषताएं
1. कक्षीयडिज़ाइन: यह बायोमास उपग्रह पृथ्वी से लगभग 660 कि.मी. की ऊंचाई पर सूर्य-समकालिक ध्रुवीय कक्षा (sun-synchronous polar orbit) में चक्कर लगाएगा। यह कक्षा सुनिश्चित करती है कि उपग्रह नियमित अंतराल पर उत्तरी व दक्षिणी गोलार्धों पर पृथ्वी के सभी क्षेत्रों को कवर करेगा, जिसमें उष्णकटिबंधीय, समशीतोष्ण, और बोरीयल वन (tropical, temperate, and boreal forests) शामिल हैं। उपग्रह का पुनरावृत्ति चक्र ऐसा है कि यह हर 25 दिनों में एक ही क्षेत्र को दोबारा स्कैन करेगा, जिससे समय के साथ परिवर्तन की निगरानी संभव होगी।
2. अनूठीरडारतकनीक: सामान्य उपग्रह प्रकाशीय कैमरे या एल-बैंड (आवृत्ति 1000-2000 मेगाहर्ट्ज) रडार का उपयोग करते हैं। लेकिन बायोमास उपग्रह में पी-बैंड रडार (P-band radar technology) का इस्तेमाल हो रहा है, जो एक कम आवृत्ति माइक्रोवेव (300-1000 मेगाहर्ट्ज़) सिग्नल प्रेषित करता है, जिससे मिट्टी और घने जंगलों के अंदर तक पैठ बना सकती है। इसका मतलब, यह पेड़ की केवल ऊपरी नहीं बल्कि अंदर तक जानकारी जुटाता है, जैसे पेड़ की ऊंचाई, तने की मोटाई और घनत्व वगैरह।
यह तकनीक दिन-रात और मौसम से बेफिक्र डैटा संग्रह करने में सक्षम है, क्योंकि रडार बादलों और बारिश से अप्रभावित रहता है। यह पहला मौका है जब कोई उपग्रह इतनी कम आवृत्ति पर काम करेगा। गौरतलब है कि पी-बैंड रडार तकनीक को लेकर सुरक्षा सम्बंधी नियम भी हैं क्योंकि इसका उपयोग रक्षा और संचार में भी होता है। लेकिन पृथ्वी को बचाने के लिए यह डैटा इकट्ठा करने हेतु युरोपीय अंतरिक्ष एजेंसी को पी-बैंड के उपयोग की विशेष अनुमति दी गई है (forest density mapping, tree height detection, forest structure analysis)।
3. पोलेरिमेट्रिकऔरइंटरफेरोमेट्रिकडैटा: इन तकनीकों का मदद से वन की संरचना (जैसे, पत्तियां, तने, ज़मीन) को अलग-अलग पहचाना जा सकता है। इंटरफेरोमेट्रिक तकनीक से सतह की ऊंचाई और 3-डी संरचना मापी जाती है। टोमोग्राफिक एसएआर से वन की ऊर्ध्वाधर परतों (चंदवे, तनों, ज़मीन) का 3डी मॉडल बनाया जाता है।
4. वैश्विककवरेज: उपग्रह हर 6 महीने में पूरी पृथ्वी को स्कैन करेगा। लक्ष्य यह है कि धरती के लगभग 30 करोड़ वर्ग किलोमीटर वन क्षेत्र को कवर किया जाए। सरल शब्दों में कहा जाए तो बायोमास उपग्रह धरती के पेड़ों का एक्स-रे स्कैन करेगा, ताकि हम जान सकें कि पृथ्वी पर कितने पेड़ हैं, उनमें कितना कार्बन है और जंगल किस गति से घट-बढ़ रहे हैं। यह उपग्रह इतनी बारीकी से स्कैन कर सकता है कि 20-20 वर्ग मीटर तक के छोटे इलाके में भी पेड़ के बायोमास का पता चल सकेगा। यह मिशन हमारे ग्रह को बचाने के बड़े अभियानों का एक अहम हिस्सा है।
कवरेज की बात करें तो बायोमास उपग्रह उष्णकटिबंधीय वर्षावनों (अमेज़ॉन, कांगो), समशीतोष्ण वनों (उत्तरी अमेरिका और युरोप के जंगल) और बोरीयल वनों (साइबेरिया और कनाडा के टैगा) को कवर करेगा। यद्यपि उपग्रह का प्राथमिक लक्ष्य वन हैं, यह मिट्टी और सतह की जानकारी (जैसे रेगिस्तान या बर्फीले क्षेत्र) भी एकत्र कर सकता है, लेकिन इन क्षेत्रों में इसकी उपयोगिता सीमित है।
जैव पदार्थ सम्बंधी डैटा कार्बन चक्र को समझने और ग्रीनहाउस गैस उत्सर्जन को कम करने की रणनीतियों में मदद करता है। उपग्रह अवैध कटाई, वन क्षरण, और पुनर्जनन की वैश्विक निगरानी करेगा, जो नीति निर्माण और संरक्षण प्रयासों के लिए महत्वपूर्ण है। वैश्विक डैटा पारिस्थितिकी, जैव-विविधता, और भू-विज्ञान के अध्ययन में उपयोगी है और अंतर्राष्ट्रीय समझौतों के लिए आधार प्रदान करेगा। कुल मिलाकर यह मिशन धरती के जंगलों के एक्स-रे निरीक्षण (x-ray monitoring) जैसा है, जिससे हम जान पाएंगे कि पृथ्वी कैसे सांस ले रही है! (स्रोत फीचर्स)
नोट: स्रोत में छपे लेखों के विचार लेखकों के हैं। एकलव्य का इनसे सहमत होना आवश्यक नहीं है। Photo Credit : https://upload.wikimedia.org/wikipedia/commons/thumb/f/fa/ESA_Biomass_Satellite_seeing_wood_through_trees.png/1024px-ESA_Biomass_Satellite_seeing_wood_through_trees.png
यहां दी गई तस्वीर को ध्यान से देखिए। आपके ख्याल से यह किसकी तस्वीर है? यदि आपका कहना है कि यह तो किसी सूखी सी, मुड़ी हुई पत्ती की तस्वीर है तो इस कीट की युक्ति सफल हुई है और आप धोखा खा गए हैं। वास्तव में, इस तस्वीर में जो दिखाई दे रहा है वह कोई पत्ती नहीं बल्कि एक तरह का पतंगा (Eudocima salaminia) (camouflage moth) है। इस पतंगे के पत्ती सरीखे शरीर का उद्देश्य ही है अपने शिकारियों को चकमा देना ([mimicry in insects], [natural camouflage]) और उनसे बचना। और, मज़ेदार बात यह है कि सिर्फ हम-आप या इसके शिकारी ही नहीं बल्कि एआई (कृत्रिम बुद्धि – artificial intelligence) भी इसके इस रूप-रंग के कारण धोखा खा गया और इसे पत्ती या पेड़ की छाल मान बैठा।
बताते चलें कि यह पत्तीरूपिया पतंगा मुख्यत: भारत और दक्षिण-पूर्व एशिया (India and Southeast Asia insects) में पाया जाता है, और साइट्रस फलों (जैसे नींबू, संतरा, मौसंबी) को पसंद करता है।
अब आते हैं इस बात पर कि एआई ने इसे कहां देख लिया और कैसे धोखा खा गया। असल में शोधकर्ता डीप लर्निंग एआई (deep learning model, AI in biology) से छद्मावरणधारी छह तरह के पतंगों की 3-डी तस्वीर बनवाना चाह रहे थे। इसके लिए उन्होंने पैटर्न पहचानने में दक्षता रखने वाले एक डीप लर्निंग एआई को जानकारी के तौर पर उन्हीं पतंगों की 2-डी तस्वीरें दिखाई जिनकी 3-डी तस्वीर उन्हें बनवानी थी। इन्हीं छह पतंगों में Eudocima salaminia पतंगे की तस्वीरें भी शामिल थीं।
बस यहीं एआई पतंगे के शरीर का पैटर्न समझने में धोखा खा गया और उसने Eudocima salaminia की पतंगेनुमा तस्वीर बनाने की बजाय मुड़े हुए पत्ते या पेड़ की छाल जैसी 3-डी छवियां बना डालीं। यह खबर शोधकर्ताओं ने जर्नल ऑफ दी रॉयल सोसाइटी इंटरफेस (journal of royal society interface) में प्रकाशित की है।
अब आगे वैज्ञानिक एआई को अलग-अलग दिशा से आती रोशनी में खींची गई और अलग-अलग पृष्ठभूमि में खींची गई तस्वीरें दिखा कर देखना चाहते हैं कि क्या इन प्राकृतिक परिवेश (natural environments) में भी एआई धोखा खाता है या पत्ती और पतंगे में भेद कर पाता है। साथ ही वे शिकारियों को धोखा देने के उद्देश्य के अलावा अन्य उद्देश्य से छद्मावरण धारण करने वाले विभिन्न जीवों पर भी ऐसे प्रयोग करके देखना चाहते हैं। (स्रोत फीचर्स)
नोट: स्रोत में छपे लेखों के विचार लेखकों के हैं। एकलव्य का इनसे सहमत होना आवश्यक नहीं है। Photo Credit : https://pbs.twimg.com/card_img/1917679665671540736/8zemDjkR?format=jpg&name=small
हमारी दृष्टि कई मामलों में सीमित है। पहला, हम प्रकाश वर्णक्रम (light spectrum) के केवल एक छोटे हिस्से को ही देख पाते हैं। हमारी देखने की क्षमता 400 नैनोमीटर (nanometer) (लाल प्रकाश) से 700 नैनोमीटर (बैंगनी) तरंगदैर्घ्य के बीच होती है। इसे दृश्यमान सीमा (visible spectrum) कहा जाता है। हम इसके बीच आने वाली तरंगदैर्घ्य के प्रकाश को ही देख पाते हैं। इससे कम तरंगदैर्घ्य (अवरक्त infrared, IR) या अधिक तरंगदैर्घ्य (पराबैंगनी ultraviolet, UV) के प्रति हम असंवेदनशील होते हैं। इसका मतलब यह नहीं है कि इस सीमा से बाहर का प्रकाश हमें प्रभावित नहीं करता – कहने का मतलब यह है कि हम इन तरंगदैर्घ्यों की सीमा के बाहर के प्रकाश को देख नहीं पाते।
दूसरा, हम लगभग 30 माइक्रॉन (micron) तक की साइज़ की वस्तु ही देख सकते हैं, इससे छोटी नहीं। अंदाज़े के लिए देखें कि 1 मि.मी. 1000 माइक्रॉन के बराबर होता है। इससे सूक्ष्म चीज़ों को न देख पाने की सीमा हमारी आंख की संरचना – लेंस (lens) और रेटिना (retina) – के कारण होती है।
इससे सूक्ष्म चीज़ों को देखने के लिए सूक्ष्मदर्शी (microscope) का उपयोग किया जा सकता है। प्रकाश सूक्ष्मदर्शी (light microscope) किसी नमूने को हमें लगभग 100 गुना बड़ा (आवर्धित magnified) करके दिखा सकता है; इसकी मदद से हम 0.3 माइक्रॉन (0.0003 मिलीमीटर) साइज़ तक की चीज़ें देख सकते हैं।
मान लीजिए, हमारे सूक्ष्मदर्शी के लेंस बढ़िया हों और रेटिना भी बेहतर हो तब भी एक सीमा (साइज़) तक की ही सूक्ष्म चीज़ों को हम देख सकते हैं। भौतिकी के नियमानुसार, किसी तरंगदैर्घ्य का प्रकाश अपनी तरंगदैर्घ्य के लगभग आधी साइज़ की वस्तु की छवि बना सकता है। यह सीमा विवर्तन (डिफ्रेक्शन – diffraction) के कारण होती है। विवर्तन यानी किसी वस्तु या अवरोध से टकराकर उसके आसपास प्रकाश तरंगों का मुड़कर आगे निकल जाना।
सरल रूप में विवर्तन को इस तरह समझ सकते हैं। यदि आप किसी तालाब में पत्थर फेंकते तो उसके चारों ओर लहरें बनती हैं, और आगे फैलती जाती हैं। पानी पर पत्तियों या छोटी डंडियों जैसे छोटे अवरोधक तैरते रहते हैं, लेकिन इनकी उपस्थिति के बावजूद दूर खड़ा दर्शक इन लहरों को समान रूप से आगे बढ़ते हुए देख पाता है, उसे लहरों में कोई उथल-पुथल नहीं दिखेगी। लेकिन, यदि पानी पर तैरने वाला अवरोधक लहर की साइज़ (wavelength) (यानी दो क्रमागत लहरों के बीच की दूरी) से बड़ा होता है तो लहरें विकृत हो (टूट) जाती हैं। संक्षेप में, लहर की साइज़ से छोटी वस्तुएं लहरों में परिवर्तन नहीं कर पातीं, जबकि उससे बड़ी वस्तुएं ऐसा कर पाती हैं।
ऐसा ही प्रकाश (light waves) के साथ भी होता है। प्रकाश केवल तभी प्रतिबिंब (image formation) बना सकता है जब वह बाधित किया जाता है। इसलिए बहुत छोटी वस्तुओं (तरंगदैर्घ्य से छोटी वस्तुओं) का प्रतिबिंब नहीं बन सकता। और यह सीमा है 300 नैनोमीटर, यानी तरंगदैर्घ्य के लगभग आधे के बराबर।
इस विभेदन सीमा (resolution limit) से पार पाने के लिए वैज्ञानिकों ने कई जुगाड़ किए हैं। इनमें से एक है अत्यंत लघु तरंगदैर्घ्य के प्रकाश (short wavelength light) और विशेष स्क्रीन का उपयोग करना। अलबत्ता, यह तरकीब हमें बहुत दूर तक नहीं ले जा सकती। बहुत सूक्ष्म चीज़ों को फिर भी नहीं देख पाते। इसके अलावा, अत्यंत लघु तरंगदैर्घ्य (जैसे एक्स-रे) हानिकारक हो सकती हैं और इसलिए केवल निर्जीव वस्तुओं के अवलोकन में उपयोगी होती हैं।
दूसरी तकनीक है इलेक्ट्रॉन सूक्ष्मदर्शी (electron microscope)। इसमें इलेक्ट्रॉन्स के तरंग गुणों का उपयोग करके छवि बनाई जाती है। (क्वांटम यांत्रिकी के मुताबिक इलेक्ट्रॉन से सम्बद्ध तरंग की तरंगदैर्घ्य लगभग 10-10 मीटर होती है।) लेकिन ये भी मृत कोशिकाओं (dead cells) या वायरस (virus imaging) जैसी निर्जीव वस्तुओं तक ही सीमित हैं।
फिर, पिछले करीब 10 सालों में लेज़र द्वारा उद्दीप्त उत्सर्जन (stimulated emission) और (जिसकी छवि बनानी है उस) वस्तु के अणुओं की कुछ क्वांटम यांत्रिक विशेषताओं का उपयोग करके सूक्ष्म चीज़ों की छवि बनाने का तरीका विकसित किया गया है। इस तकनीक को सुपररिज़ॉल्यूशन माइक्रोस्कोपी (super-resolution microscopy) कहा जाता है।
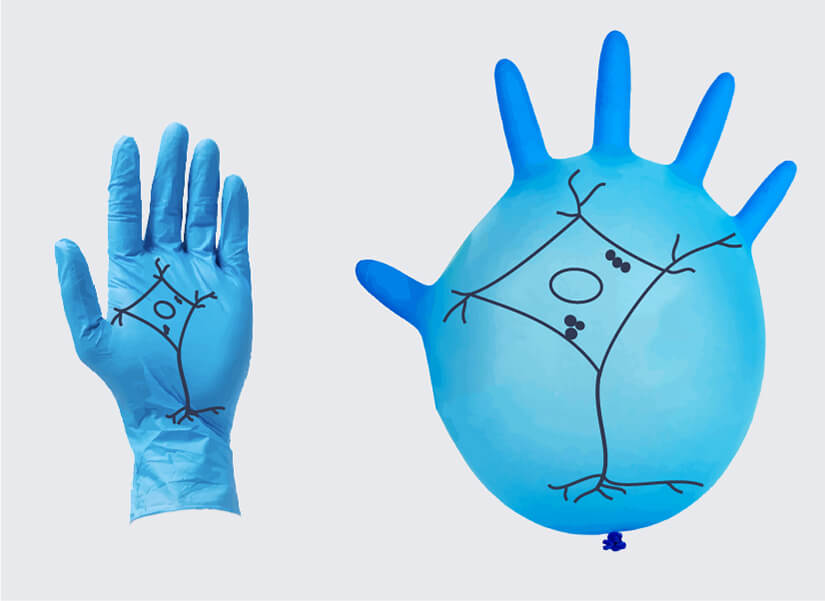
हाल ही में, इसी काम के लिए एक्सपांशन माइक्रोस्कोपी (expansion microscopy – विस्तार सूक्ष्मदर्शिकी) नामक एक और तकनीक विकसित की गई है। यह तकनीक एक सर्वथा अलग सिद्धांत पर आधारित है, जो काफी सरल है। मान लीजिए कि जिस सूक्ष्म वस्तु का अवलोकन करना है उसे किसी तरीके से, हर तरफ समान रूप से फैलाया जाए; जैसे हम किसी गुब्बारे में हवा भरकर उसे फुला कर फैलाते हैं। अब, जब यह गुब्बारा थोड़ा फूला हुआ हो तब हम इस पर तीन चिन्ह (बिंदु) अंकित करते हैं, और उन बिंदुओं के बीच की दूरी को माप लेते हैं। अब यदि गुब्बारे के आयतन को 125 गुना तक फैलाते हैं, और यदि गुब्बारा एक समान रूप से फैलता (फूलता) है तो प्रत्येक बिंदु के बीच की दूरी 5 गुना बढ़ जाएगी। इससे हम उन सूक्ष्म लक्षणों को देख पाएंगे जिन्हें पहले नहीं देख पाए थे।
सूक्ष्म वस्तुओं को देखने के लिए भी यही तरकीब अपनाई जा सकती है। ज़ाहिर है, गुब्बारे की तरह हम उन सूक्ष्म वस्तुओं में हवा भरकर फुला तो नहीं सकते। अलबत्ता हम कुछ ऐसे रसायन (chemical reagents) अवश्य खोज सकते हैं जो सूक्ष्म चीज़ों की संरचना को तोड़े बिना उनके अंदर प्रवेश कर जाएं और उनको फैला दें।
यदि वस्तु का फैलाव पर्याप्त हो जाता है तो वस्तु की बनावट की बारीकियों को साधारण प्रकाश और एक कॉन्फोकल माइक्रोस्कोप से देखा जा सकता है। हालांकि, यह सुनिश्चित होना चाहिए कि वस्तु में रसायन प्रवेश कराने पर वह सभी जगह से एक समान रूप से फैले। ऐसी स्थिति में ही इस तरह प्राप्त आवर्धित छवि विश्वसनीय होगी यानी सारे बिंदु मूल वस्तु के समान ही प्रदर्शित होंगे। यह सुनिश्चित करने के लिए हम इस संभावना का सहारा लेते हैं कि वस्तु में अणु किन्हीं बिंदुओं पर बाहरी रसायन से बंध जाएंगे। वस्तु और रसायन के बंधने के ये स्थान एंकर पॉइंट के रूप में काम करते हैं: कुछ-कुछ फुटबॉल के शीर्ष या जोड़ बिंदुओं की तरह (यानी वे बिंदु जहां फुटबॉल के काले और सफेद बहुभुज मिलते हैं), जो फुटबॉल में हवा भरने पर फुटबॉल की गोलाई (बनावट) को बनाए रखते हैं।
विस्तार माइक्रोस्कोपी एक बहु-चरणीय प्रक्रिया है। इसका मूल कार्य है – नमूने के अंदर एक बहुलक तंत्र का निर्माण करना और फिर इस बहुलक तंत्र को सममित ढंग से फुलाना।
विस्तार माइक्रोस्कोपी के क्रमवार चरण हैं – अभिरंजन (staining – स्टेन) करना, बंध बनाना (cross-linking), विगलित करना (digestion) और विस्तार करना (expansion)। स्टेन करने के चरण में फ्लोरोफोर (fluorophore molecules – दीप्ति बिखेरने वाले अणु) कोशिका में डाले जाते हैं। ये अगले चरण में बहुलक तंत्र से जुड़ जाते हैं। बंधन या लिंकिंग चरण में कोशिकाओं में बहुलक जेल डाला जाता है, जो पूरे नमूने में फैल जाता है। विगलन चरण में एक विलयन कोशिका में डाला जाता है जो कोशिका को पचा डालता और कोशिका से संरचना को हटाता है। यह चरण बहुत अहम चरण होता है, यदि यह चरण विफल हो जाता है तो नमूना ढह या टूट सकता है। अंत में, विस्तारण चरण में जेल सभी तरफ फैल जाता है। जेल से जुड़े फ्लोरोफोर अणु भी पूरे नमूने में फैल जाते हैं और फैले हुए नमूने में नया स्थान ग्रहण कर लेते हैं। चूंकि जेल चारों ओर एक समान रूप से फैलता है, फ्लोरोफोर के अणुओं के बीच एक आनुपातिक अंतराल बना रहता है।
उच्च विभेदन (high-resolution imaging) वाले प्रतिबिंब बनाने के अन्य तरीकों की तुलना में विस्तार माइक्रोस्कोपी का एक लाभ यह है कि इसके लिए जीवविज्ञान प्रयोगशालाओं (biology labs) में उपलब्ध सूक्ष्मदर्शी के अलावा अन्य किसी विशेष उपकरण की ज़रूरत नहीं होती है। इस तरीके की एक कमी यह हो सकती है कि नमूने को एक समान रूप से फैलाने वाले, नमूने को स्थिर रखने वाले, और चिन्हित करने वाले पॉलीमर या फ्लोरोफोर न मिलें। वर्तमान में एक्सपांशन माइक्रोस्कोपी से कॉन्फोकल माइक्रोस्कोप (confocal microscope) का उपयोग करके 70 नैनोमीटर तक की सूक्ष्म चीज़ें देखी जा सकती हैं, अन्य तरीकों से केवल 300 नैनोमीटर तक देख पाना संभव है। (स्रोत फीचर्स)
नोट: स्रोत में छपे लेखों के विचार लेखकों के हैं। एकलव्य का इनसे सहमत होना आवश्यक नहीं है। Photo Credit : https://abberior.rocks/wp-content/uploads/KB_ExM_Fig1_gloves.jpg
हम जगह-जगह पर कृत्रिम बुद्धि (आर्टिफिशियल इंटेलिजेंस – AI) के इस्तेमाल के बारे में सुनते रहते हैं। आम लोगों के लिए एआई का मतलब अधिकतर रोबोट होता है। लेकिन ऐसे कंप्यूटर प्रोग्राम्स (computer programs) का उपयोग बहुत अलग-अलग क्षेत्रों में किया जाता है जो खुद सीखते हैं और सीख-सीखकर खुद को बेहतर बनाते जाते हैं।
हाल ही में मेलबर्न, ऑस्ट्रेलिया में हुए 32वें एसोसिएशन फॉर कंप्यूटिंग मशीनरी (ACM) इंटरनेशनल कॉन्फ्रेंस ऑन मल्टीमीडिया में प्रस्तुत एक पेपर में इसी तरह के एक नए उपयोग के बारे बताया गया था। कंबोडिया स्थित बोरोबुदुर चण्डी काफी प्रसिद्ध और पूजनीय बौद्ध विहार है। (इंडोनेशिया की जावा भाषा में बौद्ध मंदिरों को चण्डी कहा जाता है।) 1900 में इस चण्डी के संरक्षण (restoration) के लिए बड़े पैमाने पर कार्यक्रम शुरू किया गया था। इस संरक्षण कार्य के दौरान मंदिर के आधार पर ऐसी कई फर्शियां मिलीं जिन पर (संभवत:) बुद्ध के जीवन या जातक कथाओं के दृश्यों की नक्काशी (carvings) थी। इन फर्शियों के ऊपर पड़े मलबे को हटाकर साफ किया गया। लेकिन सुरक्षा कारणों से लगा कि ऊपरी भवन को सहारा देने के लिए एक नई दीवार बना दी जाए। नई दीवार के पीछे एक बार फिर ये फर्शियां छिप गईं। लेकिन दीवार बनाने के पहले सभी नक्काशियों का दस्तावेज़ीकरण (documentation) कर लिया गया था और उनकी बहुत सारी तस्वीरें खींची गई थीं।
सौ साल से अधिक का समय बीतने के बाद अब इन नक्काशियों की स्थिति क्या होगी कोई नहीं जानता। इसलिए यह ख्याल आया कि उपलब्ध तस्वीरों के आधार पर फर्शियों पर उन नक्काशियों को फिर से बनाना (reconstruction) चाहिए। लेकिन किसी शिल्पकार (sculptor) के लिए इतनी बड़ी संख्या में इतने बारीक विवरणों से तराशी करना बहुत भारी काम है। तो क्या इस काम में कंप्यूटर (computers) मदद कर सकते हैं? क्या तस्वीरों से 3डी फर्शियां बनाना संभव है?
आजकल ड्राइंग सॉफ्टवेयर (drawing software) में सामान्यत: दो आयामी तस्वीर से कोई आउटलाइन बनाने की क्षमता होती है। यह काम सॉफ्टवेयर द्वारा इस बात को मानकर किया जाता है कि तस्वीर में जब भी अचानक रंग बदलेगा (या गाढ़ा या गहरा रंग आएगा) तो उसके लिए एक आउटलाइन बना दी जाएगी। लेकिन नक्काशी में गहराई कैसे तय की जाए?
ब्लैक एंड व्हाइट तस्वीरों में तो हम रंग का गाढ़ापन या गहरापन (डार्क) (darkness) देखकर दूरी या गहराई का अनुमान लगाते हैं। जो जगहें गाढ़े रंग की हैं वे अधिक गहराई में या नीचे की ओर हैं; और जो जगहें ऊपर की ओर हैं वहां अधिक रोशनी पड़ रही होगी और इसलिए वे अधिक उजली होंगी। इन नियमों के आधार पर काम करने वाले मौजूदा सॉफ्टवेयर ने चण्डी की फर्शियों की त्रि-आयामी रचना तो बना दी थीं, लेकिन इनमें फर्शियों की बारीक नक्काशियों या विवरणों (जैसे चेहरे पर आंखें और नाक) का अभाव था।
इसे बेहतर करने के लिए यह सुझाव दिया गया कि एक ऐसे एल्गोरिदम (algorithm) का उपयोग किया जाए जो उजले रंग से गहरे रंग में परिवर्तन की दर को ‘भांप’ सके। यह कुछ हद तक कंटूर मानचित्र (contour map) जैसा था, जिसका उपयोग भूगोलवेत्ता (geographers) करते हैं। यदि तीखी ढलान है तो कंटूर रेखाएं पास-पास आ जाएंगी। समाधान की ओर यह एक और कदम था लेकिन एक समस्या अब भी बनी हुई थी – चेहरे की हल्की गोलाइयों और सूक्ष्म विवरण को बनाने की। इसके समाधान के लिए शोधकर्ताओं ने यह देखना-समझना शुरू किया कि हम मनुष्य इसे कैसे समझते हैं। उदाहरण के लिए हो सकता है कि एक गोल चेहरे में और चेहरे की विशेषताओं के उजलेपन (या रंग) में बहुत अधिक अंतर न हो, लेकिन क्योंकि हम जानते हैं कि यह एक मूर्ति है इसलिए हम वे बारीकियां भांप लेते हैं।
कंप्यूटर के पास इस ज्ञान का अभाव होता है और वह केवल नियम से चल रहा होता है। यहीं से एआई का काम शुरू होता है। जापान के रित्सुमीकन विश्वविद्यालय के प्रोफेसर सातोशी तनाका की टीम ने कंप्यूटर को हल्की गोलाई को ‘समझने’ और उजलेपन में मामूली फर्क भी पहचानने के लायक बनाने के लिए न्यूरल नेटवर्क (neural network) का उपयोग किया। हाल ही में प्रकाशित शोधपत्र में इसके बारे में जानकारी और परिणाम दिए गए हैं।
यह एक दिलचस्प और महत्वपूर्ण उपलब्धि है। हमारे पास कई ऐतिहासिक स्थलों (historical sites) की कई ऐसी पुरानी मूर्तियों या नक्काशियों की तस्वीरें होतीं है जो अब मौसम और समय की मार के कारण जीर्ण-शीर्ण हो चुकी हैं। इस तकनीक (technology) की मदद से उन्हें पुर्नर्निमित कर सकने की आशा जगी है। हालांकि, फिलहाल इस सॉफ्टवेयर तकनीक का परीक्षण केवल नक्काशियों (उकेरन) को पुनर्निर्मित करने के लिए किया गया है, लेकिन भविष्य में इसका इस्तेमाल अन्य तरह से तराशी गई मूर्तियों या शिल्पों के जीर्णोद्धार के लिए भी किया जा सकेगा – उन्हें कम से कम उस अवस्था तक में तो लाया जा सकेगा जब उनकी तस्वीर ली गई थी।
अगला पड़ाव है जीर्ण-शीर्ण मूर्तियों के जीर्णोद्धार में मदद के लिए एआई की सीखने की क्षमता को बढ़ाना। इसमें ज़रूरत होगी इंडोलॉजी (Indology) और आइकनोग्राफी (iconography) के मानवीय ज्ञान को कंप्यूटर तकनीकों के साथ जोड़ने की – यानी भारतीय उपमहाद्वीप की भाषाओं, ग्रन्थों, इतिहास एवं संस्कृति की जानकारी और प्रतीकों के अर्थ समझने के ज्ञान को कंप्यूटर तकनीकों से जोड़ने की। (स्रोतफीचर्स)
नोट: स्रोत में छपे लेखों के विचार लेखकों के हैं। एकलव्य का इनसे सहमत होना आवश्यक नहीं है। Photo Credit : https://news.artnet.com/app/news-upload/2024/11/GettyImages-466291427-1024×671.jpg
हाल ही में राष्ट्र संघ ने पहली अंतर्राष्ट्रीय सायबर अपराध (cyber crime) संधि को मंज़ूरी दे दी है। जैसा कि सर्वविदित है, आजकल काफी सारा कामकाज इंटरनेट (internet) के माध्यम से होता है और इसका दुरुपयोग करके कई अवैध कार्यों को अंजाम दिया जा रहा है। जहां एक ओर, इंटरनेट ने आर्थिक लेन-देन को सुगम बनाया है, वहीं इसने ऐसी गुंजाइश पैदा की है कि कुछ लोग अपने गलत इरादों को कार्यरूप दे सकें। इसी के चलते सायबर अपराधों की रोकथाम एक प्रमुख सरोकार के रूप में उभरा है और राष्ट्र संघ संधि इसी को संबोधित करने का एक साधन है।
राष्ट्र संघ ने 2017 में इस संधि को अंतिम रूप देने के लिए एक समिति का गठन किया था। तीन साल के विचार-विमर्श और न्यूयॉर्क में दो सप्ताह लंबे सत्र के बाद अंतत: सदस्यों ने सर्व सम्मति से राष्ट्र संघ सायबर अपराध निरोधक संधि को मंज़ूरी दे दी। अब इसे अनुमोदन के लिए आम सभा के समक्ष पेश किया जाएगा। ऐसा माना जा रहा है कि अनुमोदन के बाद यह संधि सायबर अपराधों से ज़्यादा कारगर ढंग से निपटने में मदद करेगी, खास तौर से मनी लॉन्ड्रिंग (money laundering) और बच्चों के विरूद्ध यौन अपराध (child exploitation) जैसे मामलों में।
आम तौर पर देशों ने इस संधि का स्वागत किया है। खास तौर से उन देशों के लिए यह एक महत्वपूर्ण पड़ाव है जिनके पास अपना सायबर इंफ्रास्ट्रक्चर (cyber infrastructure) बहुत विकसित नहीं है क्योंकि संधि में ऐसे देशों के लिए तकनीकी मदद का प्रावधान है। लेकिन कई संगठन संधि के आलोचक भी हैं। इनमें मानव अधिकार संगठन और बड़ी टेक कंपनियां (tech companies) प्रमुख हैं।
विरोधियों का मत है कि इस संधि का दायरा बहुत व्यापक है और यह सरकारों को निगरानी (surveillance) को सख्त करने की छूट देने जैसा है। जैसे, संधि में यह व्यवस्था है कि यदि कोई अपराध होता है, जिसके लिए किसी देश के कानून में चार साल से अधिक कारावास का प्रावधान है, तो वह देश किसी अन्य देश के अधिकारियों से मांग कर सकता है कि वे उस अपराध से जुड़े इलेक्ट्रॉनिक साक्ष्य (electronic evidence) उपलब्ध कराएं। वह इंटरनेट सर्विस प्रदाताओं (internet service providers) से भी डेटा की मांग कर सकता है।
मानव अधिकार संगठन ह्यूमैन राइट्स वॉच ने कहा है कि यह निगरानी का एक बहुपक्षीय औज़ार है और एक मायने में दमन का कानूनी साधन है। इसका उपयोग पत्रकारों, सामाजिक कार्यकर्ताओं, एलजीबीटी (LGBT) लोगों, स्वतंत्र चिंतकों वगैरह के खिलाफ राष्ट्रीय सरहदों के आर-पार हो सकता है। टेक कंपनियों के प्रतिनिधियों का कहना है कि यह संधि डिजिटल कामकाज (digital operations) और मानव अधिकारों के लिहाज़ से हानिकारक होगी।
दूसरी ओर, कई देशों का मत है कि इस संधि में मानव अधिकारों की सुरक्षा के लिए ज़रूरत से ज़्यादा प्रावधान जोड़े गए हैं। उदाहरण के लिए, रूस जो ऐतिहासिक रूप से इस मसौदे के लेखन का हिमायती रहा है, उसने कुछ दिन पहले यह शिकायत की है कि मसौदा मानव अधिकार सुरक्षा के प्रावधानों से लबरेज़ है। इसी तरह, अंतिम दौर में इरान ने कुछ ऐसी धाराओं को हटवाने का प्रयास किया जो ‘निहित रूप से गलत’ हैं। ऐसा एक पैरा था जिसमें यह कहा गया था कि “इस संधि की किसी भी बात की व्याख्या इस रूप में नहीं की जाएगी जिससे मानव अधिकारों तथा बुनियादी स्वतंत्रता के दमन” का आशय प्रकट हो। जैसे “अभिव्यक्ति, अंतरात्मा, मत, धर्म या आस्थाओं की आज़ादी”। विलोपन के इस प्रस्ताव के पक्ष में रूस, भारत, सूडान, वेनेज़ुएला, सीरिया, उत्तर कोरिया, लीबिया सहित 32 वोट पड़े जबकि विरोध में 102 वोट पड़े। 26 देशों ने मतदान में भाग नहीं लिया था। बहरहाल इस संधि को सर्व-सम्मति से पारित कर दिया गया। (स्रोत फीचर्स)
नोट: स्रोत में छपे लेखों के विचार लेखकों के हैं। एकलव्य का इनसे सहमत होना आवश्यक नहीं है। Photo Credit : https://www.eff.org/files/issues/un-cybercrime-1b.jpg
यूएस में जनगणना हर 10 वर्ष में होती है। इसमें नागरिकों को यह आश्वासन दिया जाता है कि उनसे सम्बंधित आंकड़े गोपनीय (confidential) रहेंगे। लेकिन यह आश्वासन रस्सी पर चलने जैसा होता है – जितनी सशक्त प्रायवेसी (privacy) होगी, आंकड़ों की सटीकता (accuracy) उतनी ही कम होती जाएगी।
इनके बीच संतुलन बनाना विवाद का विषय बन गया है। आंकड़ों को अनाम बनाए रखने के लिए जिस तकनीक का उपयोग प्रस्तावित है, वह है डिफरेंशियल प्रायवेसी (differential privacy) और इसी के समर्थकों और विरोधियों के बीच विवाद चल रहा है। विरोधियों का मत है कि डिफरेंशियल प्रायवेसी जैसी तकनीक से महत्वपूर्ण आंकड़ों की विश्वसनीयता (reliability) प्रभावित हो सकती है। तो पहले यह देखते हैं कि डिफरेंशियल प्रायवेसी क्या है और कैसे काम करती है। इसे समझने के लिए हम टेक कंपनियों (tech companies) का उदाहरण लेंगे। ये कंपनियां अपने मकसद से उपयोगकर्ताओं की जानकारी एकत्रित करने के लिए मशहूर हैं।
आजकल ये कंपनियां अपने उत्पादों और सेवाओं को बेहतर बनाने के लिए हमसे मिली जानकारी का अधिकाधिक उपयोग कर रही हैं। कंपनी के दृष्टिकोण से देखें तो यह काफी मददगार होता है। लेकिन उपभोक्ता की नज़र से देखें तो यह खतरनाक हो सकता है। उपभोक्ता का वैसे भी इस बात पर कोई नियंत्रण नहीं होता कि किस तरह की जानकारी जुटाई जा रही है। समस्या तब आएगी जब इन कंपनियों पर कोई सायबर हमला (cyber attack) सफल हो जाए और सारी संग्रहित सूचनाएं लीक हो जाएं। हाल ही में सोनी कंपनी के साथ ऐसा हो चुका है।
अर्थात उपभोक्ताओं और कंपनियों के बीच हितों का टकराव है। हितों के इसी टकराव के चलते डिफरेंशियल प्रायवेसी तकनीक का विकास हुआ है। डिफरेंशियल प्रायवेसी के चलते यह संभव हुआ है कि कंपनियां सूचनाएं एकत्रित करती रहें और उपभोक्ता की प्रायवेसी का उल्लंघन भी न हो। आप सोच रहे होंगे कि इतना सब तामझाम करने की बजाय हम सारे आंकड़ों को अनाम (anonymize) बनाकर काम क्यों नहीं चला सकते।
आंकड़ों के अनामीकरण का उपयोग उद्योगों में किया जाता रहा है, और यह सोचना सही है कि हम उपयोगकर्ताओं के आंकड़ों को पूरी तरह अनामीकृत कर सकते हैं। इसके लिए करना यह होगा कि हर आंकड़े में से व्यक्ति की पहचान करने वाले चिन्हों (आइडेंटिफायर्स) को हटा दिया जाए। आइडेंटिफायर सूचना के वे अंश होते हैं जिनकी मदद से यह पहचाना जा सकता है कि वह सूचना किस व्यक्ति-विशेष की है। अलबत्ता, आंकड़ा अनामीकरण की अपनी समस्याएं हैं।
एक बड़ी समस्या यह है कि अनामीकरण की प्रक्रिया कंपनी के सर्वर (servers) पर की जाती है और यह कहना मुश्किल है कि इन सर्वर्स पर कितना भरोसा करें। और फिर यह मुद्दा भी है कि अनामीकरण में कम-ज़्यादा का क्या अर्थ होता है।
वर्ष 2006 में नेटफ्लिक्स (Netflix) ने नेटफ्लिक्स प्राइज़ नामक एक पुरस्कार की शुरुआत की थी। इस पुरस्कार के लिए विभिन्न टीम्स को एक एल्गोरिद्म (algorithm) का निर्माण करना था जो यह भविष्यवाणी कर सके कि कोई व्यक्ति किसी फिल्म की क्या रेंटिंग करेगा। इसमें मदद के लिए नेटफ्लिक्स ने एक डैटासेट उपलब्ध कराया था जिसमें 1700 फिल्मों के 10 करोड़ रेंटिंग्स दिए गए थे। ये रेटिंग्स 4,80,000 उपयोगकर्ताओं से प्राप्त हुए थे।
नेटफ्लिक्स ने आंकड़ा अनामीकरण की उपरोक्त प्रक्रिया की मदद ली थी। इसके तहत हर आंकड़े में से उपयोगकर्ता का नाम हटा दिया गया था और कुछ रेंटिंग की जगह झूठे रेंटिंग्स डाल दिए गए थे। लगता तो है कि आंकड़े काफी अनामीकृत हैं लेकिन वास्तव में ऐसा नहीं है। टेक्सास विश्वविद्यालय के दो कंप्यूटर वैज्ञानिकों – अरविंद नारायणन और विताली श्मतिकोव ने एक शोध पत्र में दावा किया था कि उन्होंने उपरोक्त ‘अनामीकृत’ आंकड़ों को इंटरनेट मूवी डैटाबेस (IMDb) के साधारण आंकड़ों के साथ जोड़कर देखा तो वे एक-एक व्यक्ति को पहचान पाए थे। IMDb डैटा सार्वजनिक रूप से उपलब्ध है।
इस तरह के हमले को लिंकेज अटैक (linkage attack) कहते हैं और यहां तथाकथित अनामीकृत आंकड़ों को गैर-अनामीकृत आंकड़ों के साथ जोड़कर व्यक्ति की पहचान उजागर की जा सकती है।
ऐसा ही एक अन्य उदाहरण है जो ज़्यादा परेशान करने वाला है। यह उदाहरण है गवर्नर विलियम वेल्ड का। 1990 के दशक में अमेरिका सरकार के समूह बीमा आयोग ने तय किया कि वह सरकारी कर्मचारियों के अस्पताल जाने से सम्बंधित आंकड़े सार्वजनिक कर देगा। आयोग ने आंकड़ों को अनामीकृत करने के लिए उनमें से व्यक्ति के नाम, पते तथा अन्य पहचान चिन्ह हटा दिए थे।
एक कंप्यूटर वैज्ञानिक नातन्या स्वीनी (Natanya Sweeney) ने यह दर्शाने का निर्णय लिया कि अनामीकरण की इस प्रक्रिया को उलटना कितना आसान है। उन्होंने उपरोक्त प्रकाशित स्वास्थ्य रिकॉर्ड को वोटर रजिस्ट्रेशन रिकॉर्ड (voter registration records) के साथ जोड़कर देखा। उन्होंने पाया कि इस डैटा में मात्र एक व्यक्ति ऐसा था जिसके निवास का ज़िप कोड, जिसका जेंडर और जिसकी जन्म तिथि गवर्नर से मेल खाते थे। इस तरह गवर्नर वेल्ड का स्वास्थ्य रिकॉर्ड सार्वजनिक रूप से उजागर हो गया था।
अपने अगले शोध पत्र में स्वीनी ने दावा किया कि 87 प्रतिशत अमरीकियों को मात्र तीन जानकारियों के आधार पर पहचाना जा सकता है: ज़िप कोड, जन्म तिथि और जेंडर।
स्पष्ट है कि आंकड़ा अनामीकरण उतना अनामीकारक नहीं है, जितना हम सोचते हैं। और यहीं डिफरेंशियल प्रायवेसी का प्रवेश होता है। डिफरेंशियल प्रायवेसी का एक फायदा यह बताया जाता है कि इसकी मदद से उपरोक्त किस्म के सायबर हमलों को नाकाम किया जा सकता है। इसे समझने के लिए हम एक अजीबोगरीब उदाहरण का सहारा लेंगे। जैसे, यह पता करना है कि कितने लोग नाक में उंगली डालते रहते हैं।
हम एक सर्वेक्षण करते हैं जिसमें मात्र एक सवाल पूछा गया है:
“क्या आप अपनी नाक में उंगली डालते हैं?
क – हां
ख – नहीं।”
इस सवाल के जो भी उत्तर मिलेंगे, उन्हें हम एक सर्वर पर संग्रहित कर लेंगे। लेकिन इसमें हम वास्तविक उत्तर को रिकॉर्ड करने की बजाय उसमें कुछ शोरगुल (नॉइज़) जोड़ देंगे।
मान लीजिए, सर्वेक्षण के एक उत्तरदाता अनीष का जवाब है ‘हां’। यहां डिफरेंशियल प्रायवेसी का एल्गोरिद्म यह है कि एक सिक्का उछाला जाएगा। यदि सिक्का चित गिरता है तो यह एल्गोरिद्म अनीष का वास्तविक जवाब सर्वर को भेज देगा। लेकिन यदि पट आता है तो सिक्का फिर से उछाला जाएगा। इस बार यदि चित आता है तो उत्तर के रूप में ‘नहीं’ भेजा जाएगा और पट आने पर वास्तविक उत्तर सर्वर में जाएगा।
ध्यान रखें कि डिफरेंशियल प्रायवेसी का एल्गोरिद्म चित-पट पर आधारित नहीं बल्कि कहीं अधिक जटिल हो सकता है। कुल मिलाकर एल्गोरिद्म आंकड़ों में नॉइज़ जोड़ने का काम करता है।
सर्वर पर जो आंकड़े आते हैं उनमें यह नॉइज़ शामिल होता है और इसलिए हम एक-एक व्यक्ति की सूचना प्राप्त नहीं कर सकते। हो सकता है कि अनीष का जवाब ‘हां’ रहा हो लेकिन रिकॉर्ड में वह ‘नहीं’ लिखा जाएगा। दरअसल लगभग 25 प्रतिशत संभावना है कि हमारा व्यक्तिगत आंकड़ा गलत होगा। यानी आप किसी व्यक्ति के जवाब को लेकर यकीनी तौर पर कुछ नहीं कह सकते और इस वजह से आप व्यक्तियों को लेकर फैसले नहीं सुना सकते। यह बात खास तौर पर अवैध या प्रतिबंधित गतिविधियों के बारे में महत्वपूर्ण है।
चूंकि आपको पता होता है कि नॉइज़ किस तरह से शामिल किया गया है और कैसे आंकड़ों में वितरित है, तो आप इसकी भरपाई करके काफी सटीकता से यह पता लगा सकते हैं कि किसी आबादी में कितने लोग नाक में उंगली डालते हैं, हालांकि एक-एक व्यक्ति के बारे में कुछ नहीं कह पाएंगे।
हमने अपने उदाहरण को सरल रखने के लिए सिक्का उछालने वाला एल्गोरिद्म लिया था, लेकिन वास्तव में डिफरेंशियल प्रायवेसी के एल्गोरिद्म में लाप्लेस वितरण का उपयोग किया जाता है। इस एल्गोरिद्म की मदद से आंकड़ों को एक बड़े परास में फैला दिया जाता है जिससे अनामीकरण में वृद्धि होती है।
डिफरेंशियल प्रायवेसी के इस संक्षिप्त परिचय के आधार पर हम समझ सकते हैं कि इस तकनीक की खूबी यह है कि यह व्यक्तिगत सूचना की प्रायवेसी सुनिश्चित करती है जबकि उस डैटासेट के समग्र परिणामों पर कोई असर नहीं डालती। अर्थात चाहे डिफरेंशियल प्रायवेसी तकनीक का इस्तेमाल किया जाए या न किया जाए, अंतिम परिणाम समान रहेगा।
लेकिन इसके साथ दिक्कत यह है कि इसका क्रियांवयन बहुत पेचीदा होता है और इसे आंकड़ों के विशाल भंडार पर ही लागू किया सकता है। तभी आंकड़ों की सटीकता से समझौता किए बगैर इसका उपयोग किया जा सकता है।
इसकी एक और कमज़ोरी यह है कि कतिपय संवेदनशील मामलों में आंकड़ों की सटीकता तो महत्वपूर्ण होती ही है, साथ में उन आंकड़ों से जुड़े नैतिक मूल्य भी महत्वपूर्ण होते हैं। जैसे, मतदाता आंकड़ों में नॉइज़ जोड़ना स्वीकार्य नहीं हो सकता, हालांकि अंतिम परिणाम शायद एक से हों। ऐसे मामलों में डिफरेंशियल प्रायवेसी शायद सर्वोत्तम विधि न हो। अब देखते हैं कि यूएस जनगणना के संदर्भ मे गोपनीयता बनाम सटीकता की बहस क्या है।
यूएसजनगणना
हर दशक में की जाने वाली जनगणना के दौरान नागरिकों को आश्वस्त किया जाता है कि उनके द्वारा दिए गए जवाब गोपनीय रहेंगे अर्थात कोई नहीं जान पाएगा किसी व्यक्ति-विशेष ने क्या जवाब दिए थे। लेकिन यूएस सेंसस ब्यूरो के इस आश्वासन में एक अगर-मगर जुड़ा है। बहुत सशक्त गोपनीयता आंकड़ों की सटीकता को कम कर सकती है। यह मुद्दा खास तौर से इसलिए महत्वपूर्ण हो गया क्योंकि सरकार ने 2020 की जनगणना में गोपनीयता-सुरक्षा की नई विधि शामिल की। इसकी वजह से जनांकिकीविदों के बीच यह चिंता फैली कि इसकी वजह से डैटा में घटियापन बढ़ेगा। जनगणना से प्राप्त डैटा अकादमिक अनुसंधान, संसदीय क्षेत्रों के निर्धारण और संघीय बजट के आवंटन की दृष्टि से महत्व रखता है। पुरानी विधि बनाम नई विधि के बीच बहस चलती रही, जब तक कि साइन्सएडवांसेस नामक शोध पत्रिका में एक अध्ययन प्रकाशित न हो गया। इस अध्ययन ने उपरोक्त चिंताओं के संदर्भ में स्वतंत्र आंकड़े प्रस्तुत किए। विशेषज्ञों का मत है कि इस पर्चे के निष्कर्ष 2030 की यूएस जनगणना में संशोधन करके मताधिकार सम्बंधी कानूनी मुद्दों को प्रभावित करेंगे।
जनगणना के आंकड़े शोधकर्ताओं और सरकार दोनों को देश में हो रहे जनांनिक परिवर्तनों को समझने में मदद करते हैं। ये आंकड़े सरकार को स्वास्थ्य, पोषण, आवास तथा इंफ्रास्ट्रक्चर जैसी चीज़ों को लेकर नियोजन में भी मदद करते हैं। यूएस जनगणना का प्रमुख संवैधानिक कारण यह है कि इसके आधार पर यूएस संसद में प्रांतवार सीटों का आवंटन किया जाता है। इसके लिए ज़रूरी होता है कि आपके पास सबसे छोटी मतदान इकाई तक के आंकड़े उपलब्ध हों ताकि वोटिंग राइट्स एक्ट, 1965 का समुचित क्रियांवयन हो सके।
जनांकिकीविद काफी समय से आंकड़ों की सटीकता और गोपनीयता के बीच संतुलन के महत्व को जानते आए हैं। उन्होंने 1990, 2000 और 2010 में इस्तेमाल की गई विधि के कारण उत्पन्न विकृतियों से तालमेल बनाना सीख लिया था। इन तीनों जनगणनाओं में जिस विधि का सहारा लिया गया था उसे अदला-बदली (swapping) कहते हैं।
साइन्स में एक लेख प्रकाशित हुआ है: “यूएस में गोपनीयता के नाम पर जनगणना के आंकड़ों को पर्दे में रखने का एक नया तरीका आया है। यह सटीकता को कैसे प्रभावित करेगा?” इसमें अलग-अलग जनगणना ब्लॉक्स के बाशिंदों के उम्र, नस्ल, जनजातीयता और पारिवारिक गुणधर्मों सम्बंधी जवाबों की परस्पर अदला-बदली की जाएगी ताकि उनकी गोपनीयता बनी रहे। ऐसे ब्लॉक्स की संख्या लगभग 1.1 करोड़ है और प्रत्येक की औसत आबादी 23 व्यक्ति है। इसके बाद इनके आंकड़ों को ज़्यादा बड़े क्षेत्र के डैटा के रूप में समेकित कर दिया जाएगा। शोधकर्ताओं का मत है कि ऐसी अदला-बदली उन व्यक्तियों को निशाना बनाती है, जिनके जनांकिक लक्षण निराले हैं और इनकी पहचान ज़्यादा आसानी से की जा सकती है। वैसे सेंसस ब्यूरो ने यह नहीं बताया है कि उसने इस विधि का उपयोग कितनी अधिक बार किया है।
2020 की जनगणना के संदर्भ में अधिकारियों ने माना कि अदला-बदली गोपनीयता सुनिश्चित करने की दृष्टि से पर्याप्त नहीं है। अधिकारियों को लगता था कि कोई ज़िद्दी हैकर सेंसस के आंकड़ों को अन्य सार्वजनिक सूचनाओं के साथ जोड़कर व्यक्तियों की पहचान कर सकता है। जिसे हम पहले ही लिंकेज अटैक के रूप में परिभाषित कर चुके हैं।
लिहाज़ा, सेंसस ब्यूरो ने पूर्ण गोपनीयता सुनिश्चित करने के लिए अदला-बदली के स्थान पर डिफरेंशियल प्रायवेसी को अपनाया है। इस तरीके में आंकड़ों में सांख्यिकीय नॉइज़ जोड़ दिया जाता है; अधिक संवेदनशील आंकड़ों में अधिक नॉइज़ डाला जाता है।
डिफरेंशियल प्रायवेसी का आंकड़ों की गुणवत्ता पर क्या असर होगा? इसे समझने के लिए शोधकर्ताओं के एक समूह ने सेंसस ब्यूरो से निवेदन किया कि वह 2020 की जनगणना की नॉइज़युक्त मापन फाइल जारी कर दे। इस फाइल में मूल आंकड़ों पर डिफरेंशियल प्रायवेसी एल्गोरिद्म लागू करने के बाद के आंकड़े होते हैं।
काफी जद्दोजहद के बाद ब्यूरो ने 2010 की वह फाइल उपलब्ध करवाई जिसमें अदला-बदली का इस्तेमाल किया गया था और साथ ही वह फाइल दी जिसमें प्रायोगिक तौर पर 2010 के आंकड़ों पर डिफरेंशियल प्रायवेसी लागू की गई थी।
इन फाइलों का विश्लेषण करके हारवर्ड, न्यूयॉर्क और येल विश्वविद्यालय के शोधकर्ता यह तुलना कर पाए कि इन दो तरीकों का आंकड़ों की सटीकता पर क्या असर होता है। अध्ययन का नतीजा था कि डिफरेंशियल प्रायवेसी और अदला-बदली दोनों ही बड़ी आबादी (जैसे समूचे प्रांत) के संदर्भ में आंकड़ों की सटीकता बनाए रखने में बराबर कारगर हैं। लेकिन सेंसस ब्लॉक जैसी छोटी भौगोलिक इकाइयों के मामले में डिफरेंशियल प्रायवेसी ज़्यादा त्रुटियों को जन्म देती है। ये त्रुटियां खास तौर से हिस्पेनिक तथा बहु-नस्लीय आबादियों के लिए ज़्यादा होती हैं। कई बार तो त्रुटि का परिमाण किसी समूह की कुल आबादी से भी अधिक होता है। जैसे, तीन हिस्पेनिक बाशिंदों वाले ब्लॉक में डिफरेंशियल प्रायवेसी द्वारा शामिल किए गए शोर की वजह से हो सकता है कि बाशिंदों की संख्या शून्य हो जाए या छ: हो जाए।
एक मायने में अदला-बदली और डिफरेंशियल प्रायवेसी के बीच का अंतर दरअसल ब्लॉक स्तर पर नज़र आने लगता है। यह अंतर इन दो विधियों के एक मूल अंतर में निहित है। अदला-बदली के अंतर्गत किसी भी ब्लॉक की कुल और मतदान उम्र की आबादी को वैसा ही रखा जाता है। अर्थात यदि किसी ब्लॉक की जनसंख्या 23 है, तो अदला-बदली के बाद भी 23 ही रहेगी। इसके विपरीत डिफरेंशियल प्रायवेसी में ऐसी कोई गारंटी नहीं होती। इसमें जोड़ा गया नॉइज़ कुल जनसंख्या में भी परिवर्तन कर सकता है और कभी-कभी तो असंभव से आंकड़े निकल सकते हैं – जैसे बाशिंदों की ऋणात्मक संख्या या बगैर वयस्क के रह रहे बच्चे, या किसी ब्लॉक में मकान की अनुपस्थिति।
इस तरह की विसंगतियों से बचने के लिए सेंसस अधिकारी आंकड़े जारी करने से पहले इन विचित्र स्थितियों को समायोजित करते हैं। अलबत्ता, सुधार की यह प्रक्रिया नई विकृतियां पैदा कर सकती है।
बहरहाल, डिफरेंशियल प्रायवेसी बेतरतीब नॉइज़ जोड़कर बेहतर नतीजे देती है, खास तौर से इसलिए कि इस नॉइज़ के सांख्यिकीय गुणधर्म सुस्पष्ट होते हैं। इसके चलते विकृतियों को संभालना अपेक्षाकृत आसान होता है जबकि अदला-बदली विधि में विकृतियां बहुत बेतरतीब होती हैं। लेकिन कुछ शोधकर्ताओं का मत है कि यदि ऋणात्मक आंकड़ों को शून्य में तबदील कर दिया जाता है तो यह एक बड़ा नुकसान है।
यूएस सेंसस ब्यूरो 2030 की जनगणना की तैयारी कर रहा है। ऐसे में उपरोक्त निष्कर्ष डैटा की सटीकता और प्रायवेसी सुरक्षा की विधियों पर विचार-विमर्श की ज़रूरत को रेखांकित करते हैं। एक तरीका यह हो सकता है कि सेंसस ब्यूरो थोड़े कम विस्तृत आंकड़े जारी करे। इसमें अनावश्यक रूप से सांख्यिकीय त्रुटियां जोड़ना नहीं पड़ेगा। लेकिन डैटा की बारीकियां सीमित करने से शोधकर्ताओं के लिए जनांकिक परिवर्तनों का विश्लेषण करना मुश्किल होगा और नीतिगत निर्णय प्रक्रिया भी बाधित होगी।
एक महत्वपूर्ण असर यह होगा कि विभिन्न सर्वेक्षण कार्य बाधित होंगे। किसी भी आबादी के प्रतिनिधिमूलक नमूने चुनने के लिए विस्तृत आंकड़े एक अनिवार्यता होती है। इन्हीं के आधार पर तय होता है कि क्या कोई नमूना समूची आबादी का प्रतिनिधित्व करता है। और ऐसे अध्ययनों के दम पर सार्वजनिक नीतियों, आर्थिक नियोजन, सामाजिक कार्यक्रमों वगैरह का मार्गदर्शन होता है।
तो हमारे सामने डैटा की प्रायवेसी सुनिश्चित करने और सटीकता अक्षुण्ण रखने के बीच संतुलन बनाने की चुनौती है। उपरोक्त कारणों से इनके बीच संतुलन काफी महत्वपूर्ण है। (स्रोत फीचर्स)
नोट: स्रोत में छपे लेखों के विचार लेखकों के हैं। एकलव्य का इनसे सहमत होना आवश्यक नहीं है। Photo Credit : https://miro.medium.com/v2/resize:fit:786/format:webp/1*ZIHUABQCdmkT0bv6yx6oTw.png
भारत में हाथियों की आबादी करीब 25-30 हज़ार बची है। नतीजतन, इन्हें ‘लुप्तप्राय’ श्रेणि में रखा गया है। अनुमान है कि पहले हाथी जितने बड़े क्षेत्र में फैले हुए थे, उसकी तुलना में आज ये उसके मात्र 3.5 प्रतिशत क्षेत्र में सिमट गए हैं – अब ये हिमालय की तलहटी, पूर्वोत्तर भारत, मध्य भारत के कुछ जंगलों और पश्चिमी एवं पूर्वी घाट के पहाड़ी जंगलों तक ही सीमित हैं।
विशेष चिंता का विषय उनके प्राकृतवास का छोटे-छोटे क्षेत्रों में बंट जाना है: हाथियों को भोजन एवं आश्रय देने वाले वन मनुष्यों द्वारा विकसित भू-क्षेत्रों (रेलमार्ग, सड़कमार्ग, गांव-शहर वगैरह बनने) की वजह से खंडित होकर छोटे-छोटे वन क्षेत्र रह गए हैं। इस विखंडन से हाथियों के प्रजनन विकल्प भी सीमित हो सकते हैं। इससे आनुवंशिक अड़चनें पैदा होती हैं और आगे जाकर झुंड की फिटनेस में कमी आती है।
हाथियों का अपने आवास क्षेत्र में लगातार आवागमन उन्हें सड़कों और रेलवे लाइनों के संपर्क में लाता है। दरअसल, एक हथिनी के आवास क्षेत्र का दायरा लगभग 500 वर्ग किलोमीटर होता है, और टुकड़ों-टुकड़ों में बंटे अपने आवास में इतनी दूरी तय करते हुए उसकी सड़क या रेलवे लाइन से गुज़रने की संभावना (और इसके चलते दुर्घटना की संभावना) बहुत बढ़ जाती है।
सौभाग्य से, सभी हाथी-मार्गों (जिन रास्तों से वे आवागमन करते हैं) पर इस तरह के खतरे नहीं हैं। बांदीपुर, मुदुमलाई और वायनाड के हाथी गर्मियों में मौसमी प्रवास पर जाते हैं। वे पानी और हरी घास के लिए काबिनी बांध के बैकवाटर की ओर जाते हैं। अध्ययनों से पता चला है कि तमिलनाडु और केरल के बीच हाथियों के 18 प्रवास-मार्ग मौजूद हैं।
इस समस्या का एक समाधान वन्यजीव गलियारे हैं – ये गलियारे मनुष्यों के साथ कम से कम संपर्क के साथ जानवरों को प्रवास करने का रास्ता देते हैं। इसका एक अच्छा उदाहरण उत्तराखंड का मोतीचूर-चिल्ला गलियारा है, जो कॉर्बेट और राजाजी राष्ट्रीय उद्यानों के बीच हाथियों के आने-जाने (और इस तरह जीन के प्रवाह) को सुगम बनाता है। हालांकि, मनुष्यों के साथ संघर्ष का खतरा तो हमेशा बना रहता है – हाथी कभी-कभी फसलों को खा जाते हैं, या सड़कों और रेल पटरियों पर आ जाते हैं।
ट्रेनकीरफ्तार
कनाडा में हुई एक पहल ने पशु-ट्रेन टकराव को कम करने का प्रयास किया है – इस प्रयास में ट्रेन के आने की चेतावनी देने के लिए पटरियों के किनारे विभिन्न स्थानों पर जल-बुझ लाइट्स और घंटियां लगाई गई थीं। ये लाइट्स और घंटियां ट्रेन के आने के 30 सेकंड पहले चालू हो जाती थीं – इन संकेतों का उद्देश्य जानवरों में इन चेतावनियों और ट्रेन आने के बीच सम्बंध बैठाना था।
चेतावनी प्रणाली युक्त और चेतावनी प्रणाली रहित सीधी और घुमावदार दोनों तरह की पटरियों पर कैमरों ने ट्रेन आने के प्रति जानवरों की प्रतिक्रियाओं को रिकॉर्ड किया। देखा गया कि बड़े जानवर, जैसे हिरण परिवार के एल्क और धूसर भालू चेतावनी प्रणाली विहीन ट्रैक पर ट्रेन आने से लगभग 10 सेकंड पहले पटरियों से दूर चले जाते हैं, जबकि चेतावनी प्रणाली युक्त ट्रैक पर ट्रेन आने से लगभग 17 सेकंड पहले। (यह अध्ययन ट्रांसपोर्टेशनरिसर्चजर्नल में प्रकाशित हुआ है।)
घुमावदार ट्रैक पर आती ट्रेन के प्रति प्रतिक्रिया कम दिखी, संभवत: कम दृश्यता के कारण। ऐसी जगहों पर, जानवर ट्रेन की आहट का आवाज़ से पता लगाते हैं। अलबत्ता, ट्रेन आ रही है या नहीं इसकी टोह आवाज़ से मिलना ट्रेन की तेज़ रफ्तार जैसे कारकों से काफी प्रभावित होती है।
कृत्रिमबुद्धि (एआई) कीमदद
हाथियों के आवास वाले जंगलों से गुज़रते समय इंजन चालक को कब ट्रेन की रफ्तार कम करनी चाहिए? भारतीय रेलवे के पास ऑप्टिकल फाइबर केबल का एक विशाल नेटवर्क है। ये केबल दूरसंचार और डैटा के आवागमन को संभव बनाते हैं, और सबसे महत्वपूर्ण रूप से ट्रेन नियंत्रण के लिए संकेत भेजते हैं। हाल ही में शुरू की गई गजराज नामक प्रणाली में, इन ऑप्टिकल फाइबल केबल की लाइनों पर जियोफोनिक सेंसर लगाए गए हैं, जो हाथियों के भारी और ज़मीन को थरथरा देने वाले कदमों के कंपन को पकड़ सकते हैं।
एआई-आधारित प्रणाली इन सेंसर से प्राप्त डैटा का विश्लेषण करती है और प्रासंगिक जानकारियां निकालती है – जैसे आवागमन की आवृत्ति और कंपन की अवधि। यदि हाथी-जनित विशिष्ट कंपन का पता चलता है, तो उस क्षेत्र के इंजन ड्राइवरों को तुरंत अलर्ट भेजा जाता है, और ट्रेन की रफ्तार कम कर दी जाती है। ऐसी प्रणालियां फिलहाल उत्तर पश्चिम बंगाल के अलीपुरद्वार क्षेत्र में लगाई गई हैं, जहां पूर्व में कई दुर्घटनाएं हुई हैं। (स्रोत फीचर्स)
नोट: स्रोत में छपे लेखों के विचार लेखकों के हैं। एकलव्य का इनसे सहमत होना आवश्यक नहीं है। Photo Credit : https://www.sanctuarynaturefoundation.org/uploads/Article/1586787578209_railway-minister-urged-1920×599.jpg
1957 में पहले कृत्रिम उपग्रह के प्रक्षेपण के बाद पृथ्वी की कक्षा, खासकर लो अर्थ ऑर्बिट (LEO), में उपग्रहों की भरमार हो गई है; अब तक तकरीबन 14,450 उपग्रह पृथ्वी की विभिन्न कक्षाओं में छोड़े जा चुके हैं।
लेकिन ये सभी उपग्रह हमेशा सक्रिय या ‘जीवित’ नहीं रहते। अपनी तयशुदा उम्र या काम के बाद वे ‘मर’ जाते हैं। बेकार पड़ चुके उपग्रहों को वहां से हटाना होता है वरना वे अंतरिक्ष में बढ़ रही उपग्रहों की भीड़ और मलबे को और बढ़ाएंगे। इसलिए पृथ्वी की भूस्थैतिक कक्षा में स्थापित उपग्रहों को धक्का देकर अधिक ऊंचाई की ‘कब्रस्तान कक्षा’ में भेज दिया जाता है, हालांकि इस तरह अंतरिक्ष में मलबा तो बरकरार ही रहता है। वहीं पृथ्वी की करीबी कक्षा में स्थापित उपग्रहों को धीमा किया जाता है। रफ्तार धीमी पड़ने पर ये पृथ्वी के वायुमण्डल में प्रवेश करते हैं, और जलकर नष्ट हो जाते हैं। लेकिन जलकर नष्ट होने से इनमें से एल्यूमीनियम ऑक्साइड और अन्य धातु कण वायुमण्डल में फैल जाते हैं, जो खतरा साबित हो सकते हैं।
जियोफिज़िकल रिसर्च लेटर्स में प्रकाशित एक अध्ययन बताता है कि 250 किलोग्राम का एक उपग्रह वायुमण्डल में जलने पर करीब 30 किलोग्राम एल्यूमीनियम ऑक्साइड छोड़ता है। पाया गया है कि वर्ष 2022 में उपग्रहों को इस तरह ठिकाने लगाने के चलते वायुमण्डल में एल्यूमीनियम ऑक्साइड की मात्रा में 29.5 प्रतिशत (17 मीट्रिक टन) की वृद्धि हुई है। भविष्य में उपग्रह प्रक्षेपण की योजना के आधार पर अनुमान है कि वायुमण्डल में प्रति वर्ष करीब 360 मीट्रिक टन एल्यूमीनियम ऑक्साइड की वृद्धि होगी। नतीजतन ओज़ोन परत को क्षति पहुंचेगी।
इसी समस्या को ध्यान में रखते हुए क्योटो युनिवर्सिटी के शोधकर्ताओं ने लकड़ी का उपग्रह, लिग्नोसैट (LignoSat), बनाया है। शोधकर्ताओं का कहना है कि लिग्नोसैट पारंपरिक उपग्रहों में इस्तेमाल की जाने वाली धातुओं की तुलना में अधिक टिकाऊ और कम प्रदूषणकारी है। शोधकर्ताओं का कहना है कि अपना काम समाप्त कर जब यह पृथ्वी पर वापस आएगा तो इसकी लकड़ी पूरी तरह से जल जाएगी और केवल जलवाष्प और कार्बन डाईऑक्साइड वायुमण्डल में मुक्त होगी। लकड़ी से उपग्रह बनाने का जो एक और फायदा दिखाई देता है वह है कि यह अंतरिक्ष के पर्यावरण को झेल सकता है और रेडियो तरंगों को अवरुद्ध नहीं करता है, जिसके चलते एंटीना को इसके अंदर लगाया जा सकता है।
घनाकार लिग्नोसैट की लंबाई-चौड़ाई-ऊंचाई लगभग 10-10 सेंटीमीटर है। इसका ढांचा मैग्नोलिया लकड़ी का बनाया गया है। इस पर सौर पैनल, सर्किट बोर्ड और सेंसर लगाए गए हैं जिनकी मदद से लकड़ी पर पड़ रहे दबाव, तापमान, भू-चुंबकीय बलों और विकिरण को मापा जाएगा। साथ ही साथ इससे रेडियो सिग्नल भेजने और प्राप्त करने की क्षमता का परीक्षण भी किया जाएगा। इसकी तख्तियों को जोड़ने के लिए गोंद या स्क्रू की बजाय लकड़ी जोड़ने की पारंपरिक जापानी विधि से एल्यूमीनियम के फ्रेम में कसा गया है।
लिग्नोसैट को इस साल सितम्बर में प्रक्षेपित किया जाएगा। उपग्रह की लकड़ी की तख्तियां वास्तविक परिस्थितियों में कितना कारगर रहती हैं यह तो कक्षा में पहुंचकर काम शुरू करने के बाद ही अच्छे से स्पष्ट होगा। यदि सफल रहा तो भावी अंतरिक्ष मिशनों में लकड़ी के उपयोग की संभावना बढ़ सकती है।
हालांकि लिग्नोसैट जलने पर मात्र जलवाष्प और कार्बन डाईऑक्साइड ही छोड़ता है लेकिन कार्बन डाईऑक्साइड की समस्याओं से भी हम भलीभांति अवगत हैं। इसलिए बड़े पैमाने पर लकड़ी-उपग्रहों के उपयोग के पर्यावरणीय असर का आकलन भी ज़रूरी है। (स्रोत फीचर्स)
नोट: स्रोत में छपे लेखों के विचार लेखकों के हैं। एकलव्य का इनसे सहमत होना आवश्यक नहीं है। Photo Credit : https://images.nature.com/lw1200/magazine-assets/d41586-024-01456-z/d41586-024-01456-z_27173294.jpg
जानलेवा सैन्य हथियारों की स्वायत्तता इन दिनों गहन विचार मंथन और चर्चाओं के दौर से गुज़र रही है। कृत्रिम बुद्धि निर्देशित जानलेवा स्वायत्त हथियारों के सृजन को रोकने के लिए अंतर्राष्ट्रीय स्तर पर अभियान शुरू हुआ है। जुलाई 2023 में संयुक्त राष्ट्र सुरक्षा परिषद द्वारा कृत्रिम बुद्धि निर्देशित हथियारों के विभिन्न पहलुओं पर व्यापक मंथन किया गया था। विचार मंथन का दौर अभी थमा नहीं है। इसी साल के उत्तरार्द्ध में संयुक्त राष्ट्र महासभा में कृत्रिम बुद्धि निर्देशित जानलेवा स्वायत्त हथियारों पर विभिन्न कोणों से नज़र डालने के लिए बैठक होगी। लेकिन इस बैठक के पहले अप्रैल में ऑस्ट्रिया में एक सम्मेलन आयोजित हो चुका है।
कृत्रिम बुद्धि निर्देशित जानलेवा स्वायत्त हथियारों की तुलना रासायनिक, जैविक और परमाणु हथियारों से की जाए तो ये हथियार खतरनाक होने के पैमाने पर एक कदम आगे निकल गए हैं। हाल के वर्षों में दुनिया की बड़ी सैन्य ताकतों ने जानलेवा स्वायत्त हथियारों को मज़बूत करने पर विशेष ज़ोर दिया है। यही मुद्दा विचार मंथन का विषय है। रक्षा वैज्ञानिक, विधिवेत्ता, रोबोट विज्ञान के अध्येता, सैन्य योजनाकार और नैतिकतावादी जानलेवा स्वायत्त हथियारों के विभिन्न मुद्दों पर बहस में जुट गए हैं।
जानलेवा स्वायत्त हथियारों पर प्रतिबंध के संदर्भ में नैतिक कारण भी अहम हैं। यह सवाल सहज रूप से किया जा सकता है कि युद्ध के मैदान में किसी भी अनैतिक गतिविधि के लिए एक मशीन को कैसे ज़िम्मेदार ठहराया जा सकता है? इस सवाल का कोई तर्क आधारित उत्तर किसी के पास नहीं है और यही कारण है कि इन हथियारों पर प्रतिबंध की मांग उठी है। नैतिक कारणों पर गंभीरता से गौर करें तो एक और बात जोड़ना लाज़मी है। क्या किसी मशीन द्वारा जीवन और मृत्यु का फैसला करना नैतिक रूप से स्वीकार्य है?
कृत्रिम बुद्धि निर्देशित जानलेवा स्वायत्त हथियारों का इस्तेमाल पिछले कई दशकों से हो रहा है। इनमें हीट सीकिंग मिसाइलें और प्रेशर ट्रिगर बारूदी सुरंगें भी सम्मिलित हैं। हाल के वर्षों में चीन, अमेरिका, ब्रिटेन, रूस और इस्राइल जैसे देशों ने युद्ध के मैदान में इन हथियारों की तैनाती को प्राथमिकता दी है। भारत ने स्वायत्त हथियारों पर अनुसंधान का समर्थन किया है।
सेना में कृत्रिम बुद्धि का इस्तेमाल जिन कुछ कार्यों के लिए किया जा सकता है, उनमें रसद और आपूर्ति प्रबंधन, डैटा विश्लेषण, खु़फिया जानकारियां जुटाने, सायबर ऑपरेशन और हथियारों की स्वायत्त प्रणाली सम्मिलित है। इनमें सबसे ज़्यादा विवादित हथियारों की स्वायत्त प्रणाली है।
क्याहैंस्वायत्तहथियार
इसके तहत वे हथियार आते हैं, जो अपने आप कार्य करने में सक्षम हैं; इन्हें मनुष्य की ज़रूरत नहीं पड़ती।
इंटरनेशनल कमेटी ऑफ दी रेड क्रॉस की परिभाषा के अनुसार स्वायत्त हथियार ऐसे हथियार हैं, जो मानवीय हस्तक्षेप के बिना लक्ष्य का चुनाव और इस्तेमाल करते हैं। वास्तव में स्वायत्त हथियार सेंसर और सॉफ्टवेयर से संचालित होते हैं। इनका इस्तेमाल उन इलाकों में किया जाता है, जहां बहुत कम आबादी होती है। दरअसल जानलेवा स्वायत्त हथियार अपने लक्ष्य की पहचान के लिए एल्गोरिदम का इस्तेमाल करते हैं।
हथियारों की यह प्रणाली ‘प्रक्षेपास्त्र प्रतिरक्षा प्रणाली’ से लेकर एक लघु ड्रोन के रूप में हो सकती है। इन हथियारों का लड़ाई के दौरान इस्तेमाल करने के कारण एक नया शब्द ईजाद किया गया है, जिसे ‘लीथल ऑटोनामस वेपन’ कहा जा रहा है। इन हथियारों का इस्तेमाल ज़मीन से लेकर अंतरिक्ष तक में किया जा सकता है, पानी पर अथवा पानी के नीचे भी किया जा सकता है। विशेषज्ञों का विचार है कि जानलेवा स्वायत्त हथियारों के सृजन में प्रौद्योगिकी की अहम भूमिका है। वस्तुत: प्रौद्योगिकी हथियारों को रफ्तार, बचाव और अन्य प्रकार की विशेषताओं से युक्त और कारगर बनाने में भूमिका निभाती है।
प्रौद्योगिकी के प्रसंग में कैलिफोर्निया युनिवर्सिटी, बर्कले के कंप्यूटर अध्येता और कृत्रिम बुद्धि से सृजित हथियारों के विरोधी स्टुअर्ट रसेल का सोचना है कि किसी सिस्टम के लिए इंसान का पता लगाकर उसे मारने की प्रौद्योगिकी क्षमता का विकास सेल्फ ड्राइविंग कार विकसित करने से कहीं अधिक आसान है।
वास्तव में पूछा जाए तो ये हथियार अब विज्ञान कथाओं के काल्पनिक भवन से बाहर निकल कर वास्तविक रूप में लड़ाई के मैदान में नज़र आ रहे हैं। इनका धीरे-धीरे विस्तार हो रहा है।
जहां एक ओर कृत्रिम बुद्धि निर्देशित जानलेवा स्वायत्त हथियारों की ज़ोरदार वकालत की गई है, वहीं दूसरी ओर इन्हें भारी विरोध और तीखी आलोचनाओं का सामना भी करना पड़ा है। आलोचकों के अनुसार ये हथियार बहुत महंगे हैं। इनका रचनात्मकता से ज़रा भी सरोकार नहीं है। भावनाओं से कोई लेना-देना नहीं है। जवाबदेही का सवाल ही नहीं उठता। एक अध्ययन में बताया गया है कि इन हथियारों के इस्तेमाल से बेरोज़गारी बढ़ेगी।
दूसरी ओर, ऐसे हथियारों की ज़ोरदार वकालत कर रहे लोगों का कहना है कि ये अत्यधिक उन्नत कार्यों को सम्पादित करने में पूरी तरह सक्षम हैं। युद्ध के दौरान मनुष्य से होने वाली त्रुटियों में कमी आएगी। ये त्वरित फैसला करने में सक्षम हैं। कुल मिलाकर, ये हथियार सटीक साबित हुए हैं और हर पल उपलब्ध हैं। इस प्रकार के हथियारों ने नए आविष्कारों और नवाचारों को भी जन्म देने में भूमिका निभाई है। पारम्परिक हथियारों की तुलना में इनसे कम नुकसान पहुंचता है, नागरिक कम हताहत होते हैं।
हाल के वर्षों में छिड़े युद्धों में कृत्रिम बुद्धि निर्देशित जानलेवा स्वायत्त हथियारों का इस्तेमाल किया गया है। इसका एक उदाहरण रूस और यूक्रेन के बीच लड़ाई है, जिसमें एआई ड्रोन का इस्तेमाल भी किया गया है। अमेरिका के रक्षा विभाग ने अपने ‘रेप्लिकेटर’ कार्यक्रम के तहत लघु हथियारयुक्त स्वायत्त वाहनों का बेड़ा तैयार किया है। इसके अलावा, प्रायोगिक पनडुब्बियां और जहाज़ बनाए हैं, जो स्वयं को चलाने के लिए कृत्रिम बुद्धि छवि का उपयोग कर सकते हैं। स्वायत्त हथियार एक मॉडल विमान के आकार का हो सकता है। इनका मूल्य लगभग पचास हज़ार डॉलर आंका गया है।
स्वायत्त हथियार प्रणालियों का समर्थन दो हिस्सों में बांटा जा सकता है। पहला, सैन्य स्तर पर फायदे और दूसरा, नैतिक औचित्य। अमेरिकी सेना के एक अधिकारी का मानना है कि युद्ध क्षेत्रों से मनुष्यों को हटाकर रोबोट का इस्तेमाल करने के नैतिक फायदे हो सकते हैं।
जुलाई 2015 में कृत्रिम बुद्धि पर आयोजित अंतर्राष्ट्रीय सम्मेलन में प्रतिभागी राष्ट्रों ने मानवीय नियंत्रण से परे स्वायत्त हथियारों पर रोक लगाने का आव्हान करते हुए एक खुला पत्र जारी किया था, जिसमें कहा गया था कि कृत्रिम बुद्धि में मानवता को फायदा पहुंचाने की क्षमताएं हैं, लेकिन अगर कृत्रिम बुद्धि निर्देशित हथियारों की स्पर्धा शुरू हो जाती है तो एआई की प्रतिष्ठा धूमिल पड़ सकती है। इस पत्र पर हस्ताक्षर करने वालों में टेस्ला कंपनी के संस्थापक एलन मस्क भी शामिल हैं। दरअसल स्वायत्त हथियार प्रणालियों के कुछ विरोध न केवल उत्पादन और तैनाती बल्कि इन पर रिसर्च, विकास और परीक्षण पर भी पाबंदी लगाना चाहते हैं।
रक्षा विज्ञान के दस्तावेज़ों में स्वायत्तता को अलग-अलग तरह से परिभाषित किया गया है। रेड क्रॉस की अंतर्राष्ट्रीय समिति के अनुसार स्वायत्त हथियार ऐसे हथियार हैं, जो स्वतंत्र रूप से लक्ष्यों का चुनाव और आक्रमण करने में सक्षम हैं। हारवर्ड लॉ स्कूल की मानव अधिकार अधिवक्ता बोनी डॉचेर्टी ने स्वायत्तता को तीन श्रेणियों में विभाजित किया है: ह्युमैन-इन-दी-लूप (निर्णय शृंखला में मानव शामिल); ह्युमैन-ऑन-दी-लूप (निर्णय शृंखला पर मानव) और तीसरा ह्युमैन-आउट-ऑफ-दी-लूप (मानव निर्णय शृंखला के बाहर) हैं। ‘निर्णय शृंखला में मानव शामिल’ श्रेणी में हथियारों की कार्रवाई इंसान द्वारा की जाती है, लेकिन लोगों को कहां और कैसे सम्मिलित किया जाना चाहिए, यह विचार मंथन का मुद्दा है। ‘निर्णय शृंखला पर मानव’ में एक मनुष्य किसी कार्रवाई को रद्द कर सकता है। ‘मानव निर्णय शृंखला के बाहर’ श्रेणी में कोई मानवीय हस्तक्षेप नहीं है। अनुसंधानकर्ताओं और सैन्य विज्ञान के जानकारों ने सैद्धांतिक तौर पर पहले प्रकार पर सहमति ज़ाहिर की है।
कृत्रिम बुद्धि से निर्देशित जानलेवा स्वायत्त हथियारों के मामले में एक महत्त्वपूर्ण मुद्दा यह भी है कि युद्ध के मैदान में इनके बेहतर प्रदर्शन का पता लगाना बेहद कठिन कार्य है क्योंकि किसी भी देश की सेना इस प्रकार की सूचनाओं का सार्वजनिक तौर पर खुलासा नहीं करती। सैन्य अधिकारी केवल इतना ही बताते हैं कि इस प्रकार के डैटा अथवा सूचनाओं का उपयोग स्वायत्त और गैर-स्वायत्त प्रणालियों के बेंचमार्क अध्ययन में किया जाता है।
परमाणु हथियारों के मामले में ‘साइट निरीक्षण’ और ‘न्यूक्लियर मटेरियल’ के ऑडिट के लिए एक अच्छी तरह से स्थापित निगरानी व्यवस्था है, लेकिन कृत्रिम बुद्धि जनित हथियारों के मामले में तथ्यों को छिपाना या बदलना बेहद आसान है।
सितंबर में संयुक्त राष्ट्र के प्रस्तावित सम्मेलन में ऐसे कुछ गंभीर मुद्दों पर विचार और निर्णय करने के लिए एक कार्य समूह गठित किए जाने के अच्छे आसार हैं। (स्रोत फीचर्स)
नोट: स्रोत में छपे लेखों के विचार लेखकों के हैं। एकलव्य का इनसे सहमत होना आवश्यक नहीं है। Photo Credit : https://media.nature.com/w1248/magazine-assets/d41586-024-01029-0/d41586-024-01029-0_26993748.jpg?as=webp